

Cluster Computing System
ระบบคลัสเตอร์ หรือคลัสเตอริ่ง เป็นการเชื่อมต่อระบบการทำงานของกลุ่มคอมพิวเตอร์เข้าด้วยกันภายใต้ระบบเครือข่ายความเร็วสูง มีความสามารถในการกระจายงานที่ทำไปยังเครื่อง ภายในระบบเพื่อให้การประมวลผลมีประสิทธิภาพสูงขึ้น โดยอาจเทียบเท่าซุปเปอร์คอมพิวเตอร์หรือสูงกว่าสำหรับการประมวลผลงานที่มีความซับซ้อนโดยเฉพาะงานด้านวิทยาศาสตร์ เช่น การจำลองโครงสร้างของโมเลกุลทางเคมี, การวิเคราะห์เกี่ยวกับตำแหน่งการเกิดพายุสุริยะ, การวิเคราะห์ข้อมูลที่มีขนาดใหญ่ เป็นต้น ถ้าดูตามโครงสร้างแล้ว ระบบคลัสเตอร์ คือคอมพิวเตอร์แบบขนานที่มีหน่วยจำแยกนั่นเอง
โครงสร้างของระบบคลัสเตอร์ แบ่งเป็น 2 ชนิด คือ
ระบบคลัสเตอร์แบบปิด คลัสเตอร์จะต่อผ่านเกตเวย์ที่ซ่อนทั้งระบบจากโลกภายนอก
ข้อดี คือ มีความปลอดภัยสูงและใช้อินเตอร์เน็ตแอดเดรสเพียงแอดเดรสเดียวเท่านั้น
ข้อเสีย คือ แต่ละโหนดในระบบไม่สามารถช่วยกันบริหารข้อมูลจากภายนอกได้
ระบบคลัสเตอร์แบบเปิด คลัสเตอร์จะต่อกับเน็ทเวิร์คภายนอกโดยตรงทำให้ผู้ใช้เข้าถึงทุกโหนดในระบบได้โดยตรง
ข้อดี คือ สามารถช่วยกันบริการข้อมูลได้ เหมาะกับงานบริการข่าวสารเป็นจำนวนมาก เช่น ในระบบเซิร์ฟเวอร์สำหรับ www หรือ ftp ที่ขยายตัวได้
ข้อเสีย คือ ความปลอดภัยต่ำลงมากเพราะต้องคอยดูแลทุกเครื่องในระบบ และยังต้องการหมายเลขอินเตอร์เน็ทแอดเดรสจำนวนมาก

คอมพิวเตอร์แต่ละเครื่องในระบบคลัสเตอร์จะถูกเรียกว่า “โหนด (Node)” อาจจะมีโหนดที่ทำหน้าที่ควบคุมการทำงานของโหนดอื่น ๆ ในระบบอีกชั้น เรียกว่า “Front-end Node” ส่วนโหนดอื่นจะทำหน้าที่ประมวลผลเป็นหลัก เรียกว่า “Compute Node” แต่ละโหนดจะสร้างระบบที่เสมือนเป็นเครื่องเดียว โดยใช้วิธีการต่าง ๆ เช่น การใช้งานระบบ Network Information System (NIS) เพื่อให้ผู้ใช้ (User) สามารถใช้งานร่วมกันได้ทุกโหนด ทำให้ผู้ใช้สามารถล็อกอิน (Login) เพื่อใช้งานในโหนดใด ๆ ภายใต้ระบบคลัสเตอร์เดียวกัน นอกจากนั้นภายในระบบคลัสเตอร์อาจจะมีการใช้งานซอฟต์แวร์ต่าง ๆ เพื่อการติดตั้งใช้งาน, การจัดลำดับงานที่ทำในระบบ, การดูแลบริหารระบบ และซอฟต์เพื่อการประมวลผลแบบขนาน (Parallel Computing)
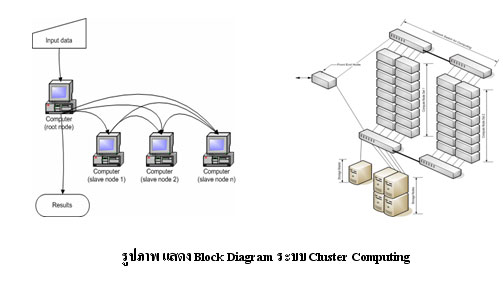

การติดตั้งระบบคลัสเตอร์ (Installation Clustering System)
เมื่อเตรียมอุปกรณ์ที่จะนำมาทำคลัสเตอร์ (เครื่องคอมพิวเตอร์สมรรถนะสูง, ระบบเครือข่ายความเร็วสูง) จากนั้นเตรียมซอฟแวร์ในระบบคลัสเตอร์ เช่น ระบบปฏิบัติการ (Linux, Solaris, BSD) ส่วนใหญ่มักจะเลือกใช้ลินุกซ์ (Linux) โดยลินุกซ์นั้นมีหลาย Distribution เช่น RedHat, Debian, Turbo Linux, Slackware เป็นต้น ระบบซอฟแวร์ที่ใช้ในระบบคลัสเตอร์ควรเป็นโปรแกรมแบบขนาน การโปรแกรมแบบขนานบนระบบคลัสเตอร์นั้นจะใช้วิธีการที่เรียกว่า การโปรแกรมแบบส่งผ่านข้อความ (Message Passing) การโปรแกรมในลักษณะนี้ทำได้โดย การกระจายงานขนาดใหญ่ไปยังหลาย ๆ เครื่องให้ทำงานพร้อมกัน และใช้การแลกเปลี่ยนข่าวสารผ่านเครือข่ายในการติดต่อระหว่างกลุ่มของโปรแกรมที่ช่วยกันทำงาน ระบบโปรแกรมแบบขนานที่ใช้งานเป็นมาตรฐานมีอยู่สองระบบคือ ระบบ PVM เป็นระบบที่มีมาก่อน โดยเป็นงานของ Oak Rige National Laboratory และ University of Tennessee at Knoxville และในราวปี ค.ศ. 1994 ได้มีมาตรฐานใหม่เกิดขึ้น คือ MPI ซึ่งเป็นที่ยอมรับกันอย่างกว้างขวาง และจะมาแทนที่ PVM ด้วย
โปรแกรม Utility และ Library ต่าง ๆ โปรแกรมเหล่านี้บ้างก็ช่วยให้บริหารระบบได้ดีขึ้น เช่น Library Math บางตัวที่ทำงานแบบขนานได้ เช่น Scalapack, PetSc เป็นต้น หรือ โปรแกรมสำหรับ Graphic Rendering โปรแกรมนี้มีทั้งในระบบลินุกซ์ และวินโดว์ ซึ่งสามารถทำงานแบบขนานได้โดยใช้เครื่องคอมพิวเตอร์จำนวนมากช่วยกันเรนเดอร์ (Render)
ระบบ Cluster Computing กับ ระบบ Lan (Local Area Networking)
ระบบ Cluster Computing มีส่วนสำคัญ 3 อย่างคือ เครือข่ายความเร็วสูง ระบบซอฟต์แวร์ที่สนับสนุนระบบคลัสเตอร์ และโปรแกรมประยุกต์ที่ใช้ขีดความสามารถของการประมวลผลแบบขนานหรือแบบกระจาย ส่วนระบบ Lan เครื่องทุกเครื่องที่อยู่บนระบบ LAN เป็นอิสระต่อกันไม่มีระบบซอฟต์แวร์ที่นำความสามารถของการประมวลผลแบบขนานและแบบกระจายมาใช้ แต่
ระบบ Cluster Computing กับ ระบบ Grid (Grid Computing)
ระบบ Cluster Computing เป็นการเชื่อมต่อเพื่อเพิ่มสมรรถนะของการประมวลผลด้วยเครื่องคอมพิวเตอร์ที่มีแพลตฟอร์ม (Platform) เดียวกันอยู่ในพื้นที่จำกัด ส่วน Grid Computing นั้นจะเชื่อมต่อได้ทุกแพลตฟอร์ม ไม่ว่าแต่ละแพลตฟอร์มจะห่างไกลกันเท่าไร
ระบบ Cluster Computing กับ ระบบโหลดบาลานซ์ (Load balancing)
ระบบ Cluster Computing มีการจัดกลุ่มของคอมพิวเตอร์หลายตัวเพื่อให้สามารถทำงานได้เหมือนกับเป็นคอมพิวเตอร์ตัวเดียวกัน ดังนั้นไม่ว่า ผู้ใช้เข้ามาใช้งานเครื่องใดภายในกลุ่มก็จะรู้สึกเหมือนใช้งานเครื่องเดียวกัน คุณสมบัติของการทำ Clustering คือการทำรีพลิเคท(Replication) โดยในแง่ของ Web Application คือการทำ Session Replication ซึ่งตามปกติแล้ว Session ของผู้ใช้เก็บใน Web Server เครื่องที่ผู้ใช้ใช้งานอยู่เท่านั้นแต่การทำ Clustering จะเป็นการคัดลอก Replicate Session นั้นไปยัง Web Server อื่นภายในกลุ่มด้วย ทำให้ไม่ว่าผู้ใช้จะเข้าไปใช้งานใน Server เครื่องใดก็จะมี Session ของผู้ใช้อยู่ด้วยเสมอ ส่วน Load Balancing คือการจัดกลุ่มของคอมพิวเตอร์หลายตัวเพื่อแบ่งงานกัน หรือกระจาย Load การใช้งานของผู้ใช้ไปยังคอมพิวเตอร์ภายในกลุ่ม เพื่อให้สามารถรับจำนวนผู้ใช้ที่เข้ามาใช้งานได้มากขึ้น หรือสามารถรับงานที่เข้ามาได้มากขึ้น นอกจากนั้นยังมีคุณสมบัติของ Fail Over คือหากมีคอมพิวเตอร์ใดภายในกลุ่มมีปัญหาไม่สามารถทำงานได้ ตัว Load Balancer ที่เป็นตัวแจก Load ให้คอมพิวเตอร์ภายในกลุ่มก็จะส่ง Load ไปยังเครื่องอื่นแทน จนกว่าเครื่องนั้นจะกลับมาใช้งานได้ดังเดิม การทำงานของ Load Balancer มี 3 ลักษณะด้วยกัน คือ
1. Round-Robin เป็นการส่ง Traffic ไปยัง Server ภายในกลุ่มวนไปเรื่อย ๆ
2. Sticky เป็นการส่ง Traffic โดยยึดติดกับ Session ที่ผู้ใช้เคยเข้าไปใช้งาน เช่น ถ้าผู้ใช้เคยเข้าไปใช้ใน Server ที่ 1 ภายในกลุ่ม Traffic ของผู้ใช้คนนั้นจะถูกส่งไปยัง Server 1 เท่านั้น
3. vWork Load เป็นการส่ง Traffic โดยดูที่ Performance ของ Server ภายในกลุ่มเป็นสำคัญ เช่นหาก Server 1 มีงานมากกว่า Server 2 ตัว Load Balancer จะส่ง Traffic ไปยัง Server 2
การทำ Cluster Load Balance คือการผสมผสานการทำงานทั้งสองลักษณะเข้าด้วยกัน หากเลือกใช้การทำงานแบบนี้แล้ว การใช้ Load Balance แบบ Sticky ก็จะไม่มีความหมาย เนื่องจากทุก Server ภายในกลุ่มเป็น Cluster อยู่แล้ว จึงไม่มีเหตุผลที่จะส่ง Traffic ไปให้เครื่องเดิมอีก ควรทำ Load Balance แบบ Round-Robin หรือ Work Load แทน Load Balance และ Cluster เป็น Design Pattern ที่ช่วยให้ System Archtect สามารถออกแบบระบบได้ง่ายและรวดเร็วขึ้น
การทำ Cluster ไม่จำเป็นต้องพึ่ง Feature ของ Server เป็นหลัก แต่สามารถ Develop ตัว Application ให้เป็น Cluster ได้โดยไม่ต้องพึ่ง Feature ของ Server เช่น การใช้หลักการของ File Sharing หรือ Database สามารถทำงานได้เหมือนกัน เช่นเดียวกับการทำ Load Balance ไม่ต้องหา Hardware หรือ Software พิเศษที่จะทำหน้าที่เป็น Load Balancer แต่เขียน Application เพื่อทำการกระจาย Traffic ไปยัง Server ได้เหมือนกัน โดยใช้หลักการของ Redirection เป็นต้น
การประมวลผลแบบขนาน (Parallel Processing)
Parallel processing คือ การแบ่งงานออกเป็นชิ้นเล็กให้แต่ละงานแก่ตัวประมวลผลหลาย ๆ ตัวในเวลาพร้อมกัน ประโยชน์ของการใช้วิธีการนี้ คือ แก้ปัญหาขนาดใหญ่ได้ ในเวลาที่เร็วขึ้น ลดค่าใช้จ่าย ซึ่งสามารถใช้เครื่องพีซี โดยเชื่อมต่อกันเป็นระบบคลัสเตอร์ แทนการใช้เครื่องเมนเฟรม หรือ ซุปเปอร์คอมพิวเตอร์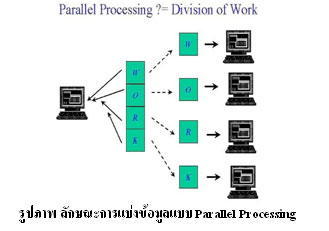
.
ทำการวิจัยคลัสเตอร์คอมพิวเตอร์ คือระบบคอมพิวเตอร์ที่ประกอบด้วยคอมพิวเตอร์มากกว่า 1 เครื่องต่อเชื่อมกัน และแต่ละเครื่องอาจมีมากกว่า 1 หน่วยประมวลผล (CPU) โดยสามารถจัดสรรให้ใช้กับ CPU, ROM, RAM ร่วมกันได้ ทำให้ได้ระบบที่มีประสิทธิภาพสูงและง่ายต่อการขยาย เพื่อการใช้ทรัพยากรการคำนวณและเข้าถึงข้อมูล ที่อยู่กระจัดกระจาย อย่างมีประสิทธิภาพสูงสุดและรวดเร็วทันต่อเหตุการณ์
ผลงานที่ผ่านมา
- โครงการสร้างซอฟต์แวร์เพื่อมาบริหารระบบคลัสเตอร์ (Cluster In Computing)
- โครงการคู่มือการสร้างและจัดการระบบคลัสเตอร์
- โครงการพัฒนาระบบการติดต่อสื่อสารภายในระบบคลัสเตอร์
- โครงการสร้างระบบคลัสเตอร์ที่สามารถเก็บข้อมูลขนาด 1 เทอราไบท์
- โครงการพัฒนาโปรแกรมที่มีการประมวลผลแบบขนาน
- Peterpan : ระบบเข้าถึงข้อมูล และการกระจายการคำนวณแบบ Web Services บน Grid
สรุป
Custer Computing คือระบบคอมพิวเตอร์ที่ประกอบด้วยคอมพิวเตอร์มากกว่า 1 เครื่องต่อเชื่อมกัน และแต่ละเครื่องอาจมีมากกว่า 1 หน่วยประมวลผล (CPU) โดยสามารถจัดสรรให้ใช้กับ CPU, ROM, RAM ร่วมกันได้ ทำให้ได้ระบบที่มีประสิทธิภาพสูงและง่ายต่อการขยาย เพื่อการใช้ทรัพยากรการคำนวณและเข้าถึงข้อมูล ที่อยู่กระจัดกระจาย อย่างมีประสิทธิภาพและรวดเร็วทันต่อเหตุการณ์
ปัจจุบันมีการแข่งขันเพื่อนำเทคโนโลยีใหม่เข้าสู่ตลาดรุนแรงขึ้น เพื่อให้สินค้าสามารถขายได้ จึงต้องเพิ่มคุณสมบัติเข้าไปในระบบของตนเพื่อความได้เปรียบ เช่น การใส่ Feature การทำ Load Balance รวมเข้ากับการทำ Clustering เข้าไปในสินค้าของตัวเอง ทำให้เครื่องคอมพิวเตอร์ส่วนบุคคล (Personal Computer : PC) มีความสามารถสูงขึ้นไม่ต่างจากเครื่องซุปเปอร์คอมพิวเตอร์ เมื่อเทียบระหว่างราคากับประสิทธิภาพที่ได้รับส่งผลให้ประสิทธิภาพสูงขึ้นมากในราคาที่เท่าเดิม ดังนั้นการเชื่อมระบบพีซีเข้าด้วยกันเพื่อทำงานเป็นซุปเปอร์คอมพิวเตอร์จึงสามารถทำได้เรียกว่า “Beowulf Cluster”
ปัญหาอีกอย่างหนึ่งที่พบเมื่อใช้ระบบราคาแพง คือ ค่าบำรุงรักษาที่สูงมาก ส่วนระบบ PC เป็นเทคโนโลยีที่คนส่วนใหญ่คุ้นเคย ทำให้สามารถบำรุงรักษาระบบได้ง่ายกว่า นอกจากนั้น เมื่อเทคโนโลยีนั้นเก่า หรือ ช้าไปแล้ว การหาทุนเพิ่มระบบจะเป็นไปได้ยาก ในขณะที่ในระบบ PC Cluster การเพิ่มความสามารถทำได้ทีละน้อยในราคาที่ถูกกว่า นอกจากนั้นเครื่องที่นำออกจากระบบยังเอาไปใช้ต่อได้ รวมถึงความก้าวหน้าของ Software เช่น ลินุกซ์ (Linux) ที่เป็นระบบปฏิบัติการฟรี (Open Source) ที่มีประสิทธิภาพสูง, ระบบโปแกรมแบบขนาน MPI (Message Passing Interface) และ PVM (Parallel Virtual Machine) ทำให้สามารถสร้างและใช้ขีดความสามารถของระบบคลัสเตอร์ได้เพิ่มมากขึ้นด้วย 
นายฆอซาลี หีมสุหรี, นางสาวภาราดา โตอุรวงศ์, นางสาวชญาน์ภักดิ์ สุพรรณ์
รุ่น MIT 9
นักศึกษาหลักสูตรวิทยาศาสตรมหาบัณฑิต (การจัดการเทคโนโลยีสารสนเทศ)
สำนักวิชาสารสนเทศศาสตร์ มหาวิทยาลัยวลัยลักษณ์
